String Match
The String Match calculation searches strings for emails, parts of filter expressions, or any other custom defined item.

Input
- Match Type
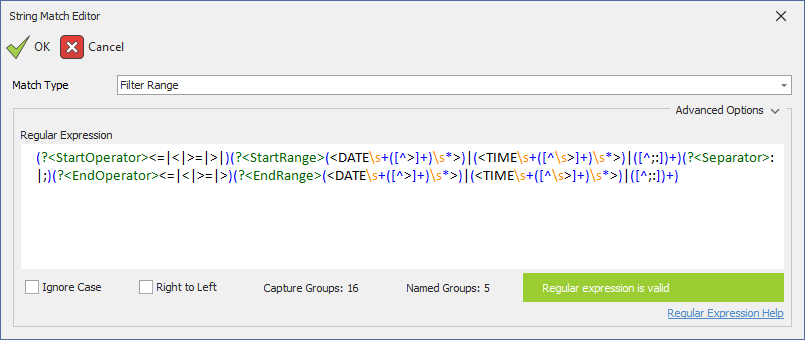
- Filter Range: Parses a range expression (ex. >10:<50) into discrete elements (see below).
- Email: Parses an email string (tom@acme.com) into 'name' and 'domain' elements.
- Custom Regular Expression: Opens a regular expression editor that allows for regular expression matching of strings.
- Ignore Case will ignore case matching for the entire search string
- Right-to-Left will search from the end of the string to the beginning
- For advanced users, see other supported in-line options that can be used.
The Match Type can also be passed in using Column Input to support dynamic regular expressions.
Output
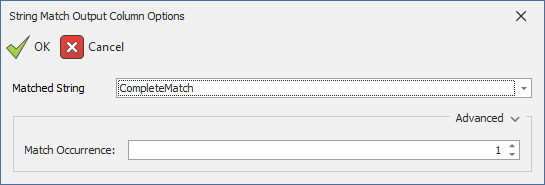
- Matched String: Based on the match type.
- Filter Range
- CompleteMatch: The entire match (ex. '>10:<50')
- StartOperator: The start range operator (ex. '>')
- StartRange: The start range value (ex. '10')
- Separator: The boolean separator value (';' for OR and ':' for AND)
- EndOperator: The end range operator (ex. '<')
- EndRange: The end range value (ex. '50')
- Email
- CompleteMatch: The entire match (ex. 'tom@acme.com')
- Email: Same as 'CompleteMatch' (ex. 'tom@acme.com')
- Name: (ex. 'tom')
- Domain: (ex. 'acme.com')
- Custom Regular Expression
- CompleteMatch
- The output is based on the number of capture groups defined in the regular expression.
- Filter Range
- Match Occurrence: In the case the match criteria finds more than one match in the string, this option indicates what match to return. Setting this property to zero will return a single concatenated string of all matches (useful to globally scrub a string).
Summary
This string matching calculation uses a textual searching language called Regular Expressions (aka 'regex'). This language uses a small set of special characters -- [\^.|?\*+() to allow for defining the criteria of the search. Acquiring a basic understanding of these characters is key to effectively using regular expressions.
Tip
Using any of these characters [\^$.|?\*+() in your criteria requires escaping by prefixing the special character with the back slash character \.
The back slash \ special character is the escape character of the language. In other words, it allows us to search for these special characters if we need to. For example, use \? to search for a question mark.
Wild Cards and Quantifiers - The Dot ., the Question Mark ?, the Asterisk *, the Plus +, and the curly brackets {}
The most basic search technique is to search for any character.
The dot . matches any single character. For any string with one or more characters, a regex of . will always return the first character. The other characters: ?,*,+,{} are for controlling how many characters to match.
?: Matches zero or one character. While.will match any non-empty string, it won't match an empty string..?will match an empty string too.*: matches zero to many characters..*will match any string, empty or not.+: matches one to many characters..+will match any non-empty string.{min matches, max matches}: controls how many matches. For example,.{2}, will match the first two characters of any string with at least two characters..{3,5}will match the first three and up to five characters of any string with at least three characters..{5,}will match the entire string of any string with at least five characters.
Character Ranges - The square bracket []
Now that we know that a dot . can match anything, the square brackets allow us to define specific characters to search for. The definition inside the brackets define the different types of characters that can be matched. For example, [ab] will match an 'a' or a 'b' (but not 'ab'). Like the dot ., the question mark ?, asterisk *, plus +, and curly brackets {} work exactly the same to match more than one (or no) character.
Key examples:
[1-9]: Match any digit 1 - 9 (but not zero)[^1-9]: Match anything but 1 - 9. The hat^inside a square bracket means 'NOT'.[A-Za-z]- Match any upper or lower case character[\s]: Any whitespace character. This is an example of a 'character class'. Other common character classes:\w: Any word character\d: Any decimal character- For advanced users, please see these supported character classes.
[\t]: Any tab character. This is an example of a 'character escape'. Other common character escapes:\n: New line\r: Carriage return- For advanced users, please see these supported character escapes
Tip
The dot and the square brackets, along with the matching quantifiers ?,*,+,{} make up the core of most all regular expressions.
Anchors - The hat ^ and dollar sign $
Anchors allow for controlling what part of the string the search criteria will focus on. The ^ anchors the criteria to the beginning of the string and the $ anchors the criteria to the end of the string. For example, ^Bike would match 'Bike Pump' but not 'A Bike Pump' while Bike$ will match 'Bike' but not 'Bike Pump'.
For advanced users, there are more advanced anchors that can be used.
Groups - The parentheses () and Bar |
The above sections provide the techniques to be able to perform basic searches for a single string. The last set of special characters allow for searching for multiple strings within a string.
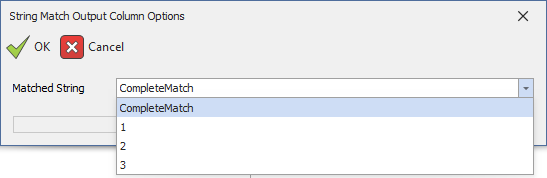
Surrounding a valid regular expression with parentheses creates a capture group. For example, the regular expression Bike(.*) with an input string of 'A Bike Pump' would have an overall match of 'Bike Pump' and a capture group of ' Pump' called '1'. Adding a second capture group would be referred to as '2'. In the string match calculation, these numbered groups will be seen in the output column dialog:
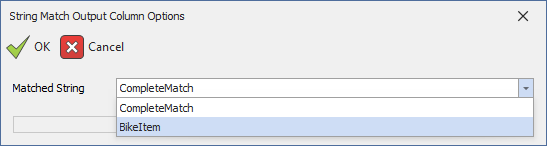
To make it easier to identify a matched group, the group can be named using a question mark and angle bracket. For example, Bike (?<BikeItem>.*) would change the capture group name from '1' to 'BikeItem'.
Grouping also supports the following useful techniques:
- Alternative searches: The
|is an OR operator between different searches. For example(Bike|Bicycle)will find either 'Bike' or 'Bicycle'. - Non-capturing groups: The
?:syntax at the beginning of a group makes it a non-capturing group. In other words, this capture group will not be seen in the output dialog. This can be a useful performance or simplification solution. - For advanced users, please see other supported grouping constructs.
References
- See the .NET Regex Language Overview for the full documentation on the regular expression engine we use.
- See our Knowledge Base Article for example usages of the calculation.